


Hace unas semanas me llamó un compañero para hacerme una consulta. Se preguntaba si existía la posibilidad de automatizar una tarea que tenía que realizar todos los días, la cual consistía en abrir una web y realizar una búsqueda, después de cubrir los campos de un formulario, y en caso de que se devuelvan resultados realizar una captura de pantalla y enviarla por correo a unos compañeros.
Sin poder ver la web, y solamente en base a esa conversación telefónica, cabría pensar que se trataría de un servicio REST con sus respectivos parámetros de filtrado, los cuales se podrían ver en la propia consola del navegador, y que bastaría con invocarlo y procesar el JSON de respuesta para determinar si hay o no resultados.
No obstante, no fue el caso: el formulario enviaba una petición POST informando los filtros como form-data, y la respuesta del servicio era en formato HTML, respuesta que podría, o no, incluir los resultados de la búsqueda en una tabla.
A raíz de esto no me quedó más remedio que buscar una librería para realizar web scraping.
En este post veremos cómo se abordó dicha tarea de automatización mediante la librería Java JSOUP dentro de un proyecto Spring Boot, el cual expondrá un único servicio REST con los mismos filtros de búsqueda que el formulario y mediante el que se procederá a realizar el envío por correo con la implementación Spring de JavaMailSender.
Aunque no es necesario disponer de unos amplios requisitos previos para entender cómo empezar a trabajar con esta librería, sí se recomienda poseer nociones básicas de orientación a objetos, así como conocer cómo realizar llamadas mediante algún cliente REST (Insomnia, Postman, Soap UI, …) y poner puntos de interrupción y depurar en un IDE (Eclipse, IntelliJ, …).
Pero antes de nada, ¿qué es el web scraping?
¿Qué es el Scraping?
Son un conjunto de técnicas empleadas para obtener de forma automática datos de una o varias páginas web.
¿Qué utilidades tiene o para qué podemos emplearlo?
Algunas de las utilidades más conocidas para estas técnicas de manipulación y análisis de información son:
- Recopilación y listado de información de distintas webs.
- Robots de los motores de búsqueda para análisis y clasificación de contenido.
- Generación de alertas.
- Monitorización de precios de la competencia.
- Detección de cambios en una web.
- Analizar enlaces rotos.
- Etc.
Cabe destacar que en España el web scraping es legal. No obstante, puede suponer en algunas ocasiones sanciones administrativas en casos de incumplimiento de RGPD (almacenamiento y tratamiento de datos de terceros sobre los que no se tiene consentimiento) o sanciones penales por delitos en contra de la propiedad intelectual.
¿Qué librerías tenemos a nuestra disposición?
Uno de los lenguajes de programación más empleados para scrapear es Python, pero también tenemos a nuestra disposición múltiples librerías para los distintos lenguajes que empleamos en nuestro día a día, por ejemplo:
- Python: Scrapy, BeautilShop.
- Javascript: Osmosis, Apify SDK.
- Java: JSOUP, Jaunt, Nutch.
Análisis inicial
Antes de empezar a abordar la automatización, es necesario realizar un análisis previo de la web en la que se va a realizar el scraping mediante herramientas de depuración web, como por ejemplo, Chrome DevTools (accesible mediante la tecla F12 una vez abierto el navegador Chrome o a través de su menú contextual: More Tools > Developer Tools).
Una vez que se hace clic en el botón de consultar, se pueden ver todas aquellas peticiones que se lanzan desde la pestaña “Network”, lo cual incluye toda la información necesaria para poder empezar a codificar la lógica de la aplicación:
- URL del servicio.
- Tipo de autenticación (si procede).
- Filtros de búsqueda (nomenclatura y formato).
- Respuesta del servicio.
Haciendo distintas llamadas, variando los filtros, podemos observar las siguientes casuísticas en la respuesta HTML:
- Si no se producen resultados, solamente se incluye una tabla (la que corresponde al formulario de búsqueda).
- Si se producen resultados, se muestran dos tablas: una primera asociada al formulario de búsqueda y una segunda con los anuncios filtrados.
- Si se produce algún error, se muestra solamente la tabla de formulario y un aviso mediante la librería Javascript Toastr.
Por tanto, para cubrir los casos anteriormente descritos, la aplicación deberá:
- Realizar una primera llamada a la web para obtener las cookies.
- Realizar la invocación al servicio informando las cookies obtenidas en el paso anterior, así como todos aquellos filtros especificados por el usuario.
- Comprobar si se ha producido algún error mediante el código de estado e inspeccionando la parte Javascript + Toastr.
- Analizar si existe la segunda tabla con los resultados obtenidos y, de ser así, transformar cada fila de dicha tabla y aplantillar la información en un DTO para, posteriormente, manipular y notificar de forma más cómoda.
Configuración
Para realizar la tarea se empleó un proyecto Maven generado a partir del inicializador de Spring de la siguiente web: start.spring.io, al que posteriormente se le añadió la dependencia JSOUP en el POM:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
Elementos clave de la librería
En el código implementado veremos varios de los elementos clave de JSOUP:
- Connection: interfaz que provee de métodos sencillos para buscar contenido en la web y parsearlos en Document.
- Request: representa una petición HTTP.
- Response: representa una respuesta HTTP.
- Document: es el objeto base de la librería en el que podemos obtener el código HTML obtenido de la dirección que estamos inspeccionando.
- Element: se trata del componente mínimo dentro de Document. A partir de él se puede extraer información, recorrer la jerarquía de nodos que lo componen y manipular el HTML. A la colección o plural de este elemento se le conoce como Elements, clase que extiende de ArrayList<Element>.
- DataNode: componente nodo de datos para contenidos de estilo, etiquetas de script, etc.
- select(): es uno de los métodos más importantes de la librería y es implementando tanto por Document como por Element y Elements. Soporta tanto jquery como buscar elementos CSS y, al tratarse de un método contextual, podemos filtrar tanto seleccionando desde un elemento específico como concatenando llamadas select.
Realizar petición y obtención de HTML
Mediante el siguiente código vemos cómo obtener las cookies, rellenar los atributos asociados al formulario y realizar la invocación al servicio, cuya respuesta, en formato HTML, estará disponible dentro de la clase Document.
// Realizamos petición a la página de la xunta para obtener las cookies
Connection.Response response = Jsoup
.connect("http://www.xunta.es/comisions")
.method(Connection.Method.GET)
.execute();
// Realizamos petición al servicio de consulta de anuncios
Document serviceResponse = Jsoup
.connect("http://www.xunta.es/comisions/ConsultarAnuncios.do")
.userAgent("Mozilla/5.0")
.timeout(10 * 1000)
.cookies(response.cookies())
.data("aberto", toString(criteria.getFinalUsers()))
.data("conselleria", toString(criteria.getCounselling()))
.data("desde", toString(formatDate(criteria.getStartDate())))
.data("ata", toString(formatDate(criteria.getEndDate())))
.data("grupo", toString(criteria.getGroup()))
.data("nivel", toString(criteria.getLevel()))
.data("provincia", toString(criteria.getProvinceCode()))
.data("concello", toString(criteria.getDistrict()))
.data("descricion", toString(criteria.getDescription()))
.post();
Analizando la respuesta
Una vez que se realiza la llamada al servicio, podemos observar, mediante el HTML que se devuelve, que no solo existen resultados si no que además existe una tabla en el contenido, la cual se corresponde con los distintos filtros que componen el formulario y, si existen resultados que satisfacen la búsqueda, tras la tabla del formulario se mostrará una segunda tabla con los resultados.
Ejemplo:
Por tanto, si quisiéramos especificar un selector que nos indique si se producen resultados, bastaría con filtrar por el elemento <table>, y ver si el número total de elementos es mayor que uno.
Y para recorrer y obtener los distintos campos de cada fila, bastaría con iterar por el número de elementos que la componen.
// Procesamos la tabla de resultados: formulario + resultados.
Elements tables = serviceResponse.select("table");
if (tables.size() > 1) {
Elements rows = tables.get(1).select("tr");
// Eliminamos la última columna de la tabla (uris relativas).
for (int i = 1; i < rows.size(); i++) {
Elements values = rows.get(i).select("td");
String destinyCenter = values.get(0).text();
String jobCode = values.get(1).text();
String denomination = values.get(2).text();
String provision = values.get(3).text();
String group = values.get(4).text();
String level = values.get(5).text();
commissions.add(new CommissionResult(destinyCenter, jobCode, denomination, provision, group, level));
}
}
Servicio REST de automatización
Para la tarea de automatización, expuse un servicio REST en el único controlador del código, el cual tiene como parámetro de entrada una dirección de correo para realizar un envío de los resultados y los mismos filtros para la búsqueda que dispone la web.
Podéis consultar toda la información sobre el servicio publicado (entrada, códigos de estado, URL, etc.) en el siguiente repositorio de Github: https://github.com/hugogldrrl/java-jsoup
/**
* Fachada de consulta de anuncios de comisiones.
* @param recipient Destinatario para notificación de resultados.
* @param filters Filtros de búsqueda.
* @return Anuncios de comisiones.
* @throws MalformedURLException URL malformada.
* @throws HttpStatusException Respuesta no correcta y bandera de ignorar errores HTTP desactivada.
* @throws UnsupportedMimeTypeException Tipo de dato en respuesta no soportado.
* @throws SocketTimeoutException Tiempo de conexión agotado.
* @throws IOException Error desconocido.
* @throws MessagingException Error en el envío del correo de notificación.
*/
@GetMapping("commission")
public List getCommissions(@Email String recipient, @Valid CommissionCriteria filters)
throws MalformedURLException, HttpStatusException, UnsupportedMimeTypeException, SocketTimeoutException, IOException, MessagingException {
LOG.info("request started -> '/xunta/commission' -> recipient ({}), filters ({})", recipient, filters);
final List commissions = xuntaService.getCommissions(filters);
if (StringUtils.isNotEmpty(recipient) && commissions.size() > 0) {
MimeMessage msg = javaMailSender.createMimeMessage();
msg.setRecipient(Message.RecipientType.TO, new InternetAddress(recipient));
msg.setSubject("Xunta's Commission Results");
msg.setContent(xuntaService.createCommissionEmailContent(filters, commissions), "text/html;charset=UTF-8");
javaMailSender.send(msg);
}
LOG.info("request finished -> results ({})", commissions.size());
return commissions;
}
Empleando el servicio implementado para extraer la información de la web, para los mismos filtros que los empleados en las capturas anteriores desde el navegador, se puede ver que se obtienen esos dos mismos resultados. Filtros aplicados:
- Destinatario del correo electrónico: “goldar@softtek.com”.
- Fecha desde: “2020-01-01”.
- Fecha hasta: “2020-01-01”.
- Usuarios finales: “F” (funcionarios).
- Código de provincia: “15” (A Coruña).
- Código de municipio: “001” (A Coruña).
La URL de la petición sería:
http://localhost:8080/jsoup/xunta/commission?recipient=hugo.goldar@softtek.com&startDate=2020-01-01&endDate=2020-01-01&finalUsers=F&provinceCode=15&district=001
La respuesta (en formato JSON) sería:
[
{
destinyCenter: "SERVIZO DE MOBILIDADE (A CORUÑA)",
jobCode: "IVC991000315001011",
denomination: "XEFATURA SECCIÓN II",
provision: "C",
group: "A1,A2,C1",
level: "25"
},
{
destinyCenter: "SERVIZO XURÍDICO-ADMINISTRATIVO (A CORUÑA)",
jobCode: "MRC991020115001005",
denomination: "XEFATURA SECCIÓN XURÍDICA",
provision: "C",
group: "A1,A2",
level: "25"
}
]
Configuración del correo
Para el envío de la notificación por correo se ha empleado una plantilla de Thymeleaf y la implementación Spring de JavaMailSender, cuya configuración se encuentra dentro del fichero “application.properties”.
Para más información sobre Thymeleaf, puede leer alguno de los posts ya publicados en nuestro blog: Thymeleaf como alternativa MVC, de Sebastián Castillo, y Thymeleaf y Flying Saucer para generar PDF, de Emilio Alarcón.
# Configuración del correo.
spring.mail.host=smtp.gmail.com
spring.mail.port=587
spring.mail.username=tucorreo@gmail.com
spring.mail.password=secret
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.connectiontimeout=5000
spring.mail.properties.mail.smtp.timeout=5000
spring.mail.properties.mail.smtp.writetimeout=5000
spring.mail.properties.mail.smtp.starttls.enable=true
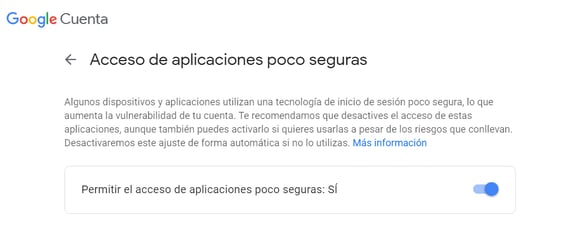
En el caso de Gmail, es necesario habilitar el acceso de aplicaciones poco seguras dentro de la configuración de la cuenta. En caso contrario, se producirá una excepción de tipo MailAuthenticationException:
org.springframework.mail.MailAuthenticationException:
Authentication failed; nested exception is javax.mail.AuthenticationFailedException:
Username and Password not accepted. Learn more at 535 5.7.8 https://support.google.com/mail/?p=BadCredentials
Para habilitar dicho acceso, puede entrar en la siguiente dirección: https://myaccount.google.com/lesssecureapps
Conclusión
En este post hemos realizado una breve demostración de cómo extraer de manera sencilla información de una web con JSOUP, una librería Java para realizar web scraping, mediante sus elementos clave Connection, Document y Element, así como poder realizar filtrados sencillos con la interfaz select que nos proporcionan.
Os animo a que descarguéis el código del proyecto del repositorio de GitHub (https://github.com/hugogldrrl/java-jsoup) y probéis a depurar e incluso a analizar cualquier otra web distinta de la usada en el proyecto.
¡No dudes en comentar si tienes cualquier sugerencia o duda… ¡y suscríbete para estar al día!



.jpg?width=352&name=architecture-asian-bird-s-eye-view-186537%20(1).jpg)