Seguro que a más de uno le extraña ver una entrada en un blog de tecnología sobre esta temática. En cierta medida ese pensamiento es razonable, de hecho hasta dudé escribir sobre ello; y es que estamos hablando de algo que está funcionando desde 1969, o incluso antes.
El caso es que tiene todo el sentido del mundo, y esta idea se me reafirmó cuando asistimos al #CommitConf2018 y pude ver que una de las ponencias era sobre Vim (Vi mejorado), que es un editor de texto en modo comando. La versión original de Vi es de 1976 y, en 2018, alguien ha decidido utilizar su espacio, en una de las conferencias más importantes que tenemos en España sobre tecnología, para hablar de ello, ¿Es una decisión acertada o por lo menos algo que no es descabellado? Obviamente, a mí me lo parece, pero cada uno tendrá su propia opinión.
En las últimas versiones de Windows, se permite instalar una consola Linux para poder utilizarla de forma nativa, lo que una vez más nos confirma que lejos de ser algo que vaya a desaparecer, cada vez lo tenemos más extendido, cercano y accesible.
Cualquier sistema operativo Unix-like, POSIX..., a los que por simplificar nos solemos referir como Linux, en su instalación más básica, nos ofrecen un conjunto de herramientas y comandos que, en algún momento, nos pueden ser de gran utilidad.
Para acceder a estos comandos lo hacemos a través de la consola, la línea de comandos, una shell, el intérprete de comandos… los nombres que se utilizan son muchos, pero al final a lo que nos estamos refiriendo es a “la pantalla negra”.
El principal problema que se suele ver en las personas que no acostumbran a utilizar la consola es el miedo, de igual manera que lo veo en mi madre con el mando de la tele: “no toco, no vaya a ser que rompa algo”. Aunque es posible que rompas algo, si tienes cuidado, no tiene por qué pasar nada. Si se introduce mal un comando, verás un error o no tendrás los resultados esperados, pero es muy difícil, que si por ejemplo estás buscando datos en un fichero, por error destruyas el servidor. Así que el primer paso es perder el miedo.
Bromas a parte, aunque para nuestro día a día no sea necesario tener que consultar nada por medio de una consola, al menos, deberíamos saber de su existencia, capacidades y limitaciones porque es posible que nos pueda sacar de un gran apuro o simplificar muchas tareas.
Desde luego no es necesario conocer absolutamente todas las funcionalidades, comandos y opciones que tenemos a la hora de realizar alguna operación. Para eso tenemos internet, donde seguramente podremos encontrar miles de ejemplos justo para lo que queremos realizar, o podemos consultar el manual del comando que queramos ejecutar. Si no estás muy familiarizado con la consola, lo más recomendable será la primera opción, ya que el manual de cualquier comando linux suele ser bastante denso, pero, una vez más, por lo menos deberíamos saber de su existencia. El manual nos mostrará las opciones que tenemos disponibles para nuestro sistema operativo. Esto es importante tenerlo en cuenta porque las opciones de un comando pueden diferir entre sistemas operativos.
En definitiva, con unos pocos comandos podemos hacer muchas cosas, y sabiendo cómo funciona un sistema operativo linux, podemos ver por dónde investigar de manera sencilla cómo hacer cosas más avanzadas.
Vamos a ver algunos de los comandos más sencillos y más utilizados, intentando cubrir los problemas más recurrentes que se suele encontrar un desarrollador, el buscar información en ficheros, que nos puede servir para localizar información de un error o configuraciones de nuestras aplicaciones.
Antes de empezar a ver cómo realizar búsquedas, es interesante que conozcamos algunos comandos que utilizaremos para movernos por el sistema de ficheros:
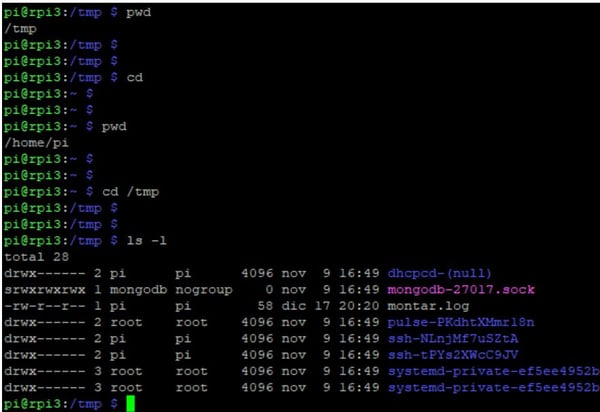
- pwd (Print Working Directory): Muestra el directorio en el que actualmente se encuentra el usuario.
- cd (Change Directory): Cambia el directorio de trabajo del usuario. Si no se le indica ningún parámetro, lo cambia por la home (directorio personal) del usuario.
- ls (LiSt): Lista el contenido de un determinado directorio o, si no le indicamos el directorio, lista el contenido del directorio actual. Además de listar el contenido se le pueden pasar distintos parámetros para extender la información que muestra.
Ahora que ya somos capaces de movernos por los directorios de una máquina, vamos a poder empezar a hacer búsquedas.
1.- BÚSQUEDA DE FICHEROS
Si queremos buscar información dentro de ficheros, lo primero que tenemos que saber es localizar los ficheros en los que tenemos que buscar. Para realizar búsquedas el comando rey es find que, como su propio nombre indica, sirve para realizar búsquedas. Tiene una gran cantidad de parámetros que nos permiten filtrar los resultados en función de un amplio abanico de parámetros.
1.1- Búsquedas generales
Es un comando que no tiene ningún parámetro obligatorio para que se pueda ejecutar correctamente. Si ejecutamos find listará recursivamente todos los ficheros y directorios que hay, partiendo del directorio en el que nos encontramos. Pero lo más interesante es utilizarlo con parámetros para afinar las búsquedas.
Para hacer búsquedas generales en un determinado directorio, únicamente tenemos que pasar como parámetro el directorio en el que queremos realizar la búsqueda.
1.2- Búsquedas por nombre
- name → Para indicar el nombre del fichero que queremos buscar. Admite comodines, por lo que no es necesario conocer el nombre completo del fichero.
- iname → Idéntico al anterior, con la diferencia de no distinguir mayúsculas y minúsculas.
1.3- Búsquedas por tipo
Si queremos afinar las búsquedas por el tipo de fichero que queremos encontrar, utilizaremos los siguientes parámetros:
- type → Para indicar el tipo de fichero, lo más utilizado es f para ficheros regulares y d para directorios.
- readable → Devolverá los ficheros que tienen permisos de lectura.
- executable → Devolverá los ficheros que son ejecutables y los directorios que tienen permisos para que se pueda buscar dentro de ellos.
- writeable → Devolverá los ficheros que tiene permiso de escritura.
- perm → Permite hacer búsquedas más detalladas que los anteriores, ya que permite que se le indiquen los permisos que debe tener el fichero. Para ello requiere los permisos de propietario, grupo y resto.
1.4- Búsquedas temporales
También podemos añadir al filtrado la fecha de modificación del ficheros:
- mtime → Para señalar el tiempo que ha pasado desde su modificación, expresado en días (24h).
- mmin → Idéntico al anterior, pero utilizando los minutos como unidad de tiempo.
1.5- Búsquedas por tamaño
- size → Para añadir el criterio del tamaño, se puede indicar que sea mayor, menor o igual a un tamaño determinado, y se puede expresar en distintas unidades. c para indicar que son bytes, k para kilobytes, M para megabytes y G para gigabytes.
1.6- Ejecución de comandos
Se permite que además de la búsqueda de ficheros, se pueda indicar la ejecución de un comando sobre los ficheros encontrados:
- exec → Ejecutará el comando que le pasamos hasta encontrar un punto y coma. Para referirnos en el comando al fichero encontrado se utiliza {}, y si queremos escapar algún carácter utilizaremos la / .
1.7- Algunos ejemplos
En los puntos anteriores hemos visto algunas opciones de las que podemos utilizar con el comando find, pero sin lugar a dudas se ve mucho más claro con algunos ejemplos de utilización.
- Listar sólo ficheros
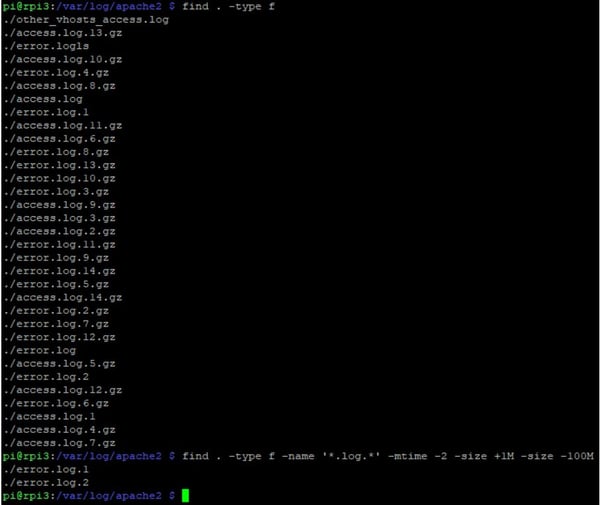
- find . -type f
- Listar sólo ficheros con un patrón determinado
Podemos buscar únicamente los ficheros que tengan en su nombre .log. (-name ‘*.log.*’), que se hayan modificados en los últimos dos días (-mtime -2 ), con un tamaño mayor a 1Mb (-size +1M ) y menores que 100Mb (-size -100M)
find . -type f -name '*.log.*' -mtime -2 -size +1M -size -100M
- Ejecutar comandos sobre ficheros.
Es posible que sobre los ficheros que hemos encontrado queramos realizar alguna acción. Para ello, el mismo comando find nos permite ejecutar comandos sobre los resultados con el parámetro exec.
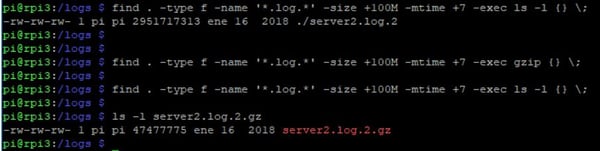
Si por ejemplo, queremos borrar (rm) los ficheros de log (-name `*.log.*` ) que ocupen más de 100Mb (-size +100Mb ) y que tengan una antigüedad de más de una semana (-mtime +7 ), ejecutaremos el siguiente comando:
- find . -type f -name '*.log.*' -size +100M -mtime +7 -exec rm {} \;
Si en lugar de borrarlos queremos conservarlos, pero tenerlos comprimidos para que ocupen menos espacio utilizaremos el comando gzip
- find . -type f -name '*.log.*' -size +100M -mtime +7 -exec gzip {} \;
2.- BÚSQUEDA EN FICHEROS
Para buscar contenido dentro de un fichero se pueden utilizar múltiples comandos, tampoco se trata de verlos todos pero sí de conocer los más representativos y algún ejemplo de su utilización.
grep, busca líneas que concuerden con un patrón en un fichero o en la entrada estándar (hago este matiz porque no solo puede buscar dentro de ficheros, puede buscar entre los datos que le devuelva otro comando). Es necesario indicarle qué queremos buscar y el fichero o ficheros donde queremos hacer la búsqueda.
- Buscar la cadena Exception en los ficheros con extensión .log y que están en el directorio /logs/
grep Exception /logs/*.log
- Buscar ficheros que contengan la cadena Exception independientemente de que esté en mayúsculas o minúsculas (-i )
grep -i Exception /logs/*.log
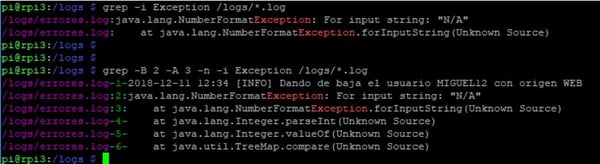
- Buscar ficheros que contengan la palabra Exception, independientemente de que esté en mayúsculas, y mostrar el número de línea (-n ) en el que aparece
grep -n -i Exception /logs/*.log
- Buscar ficheros que contengan la palabra Exception independientemente de que esté en mayúsculas, mostrar el número de línea en el que aparece, mostrando además las 2 líneas anteriores (-B 2 ) y las 3 posteriores (-A 3 )
grep -B 2 -A 3 -n -i Exception /logs/*.log
tail, muestra la última parte de un fichero. Por defecto muestra las últimas 5 líneas, pero se le puede indicar el número de líneas. Una opción muy interesante es -f, que irá sacando por pantalla todo lo que se le vaya añadiendo al fichero en tiempo real hasta que paremos la ejecución del comando.
tail -30 /logs/server.log nos mostraría las 30 últimas líneas del fichero /logs/server.log.
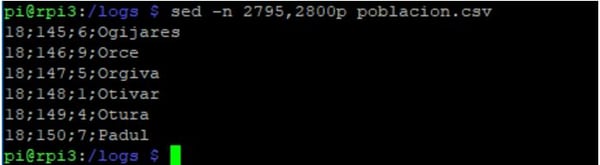
sed. Con el parámetro -n le indicamos el rango de líneas que queremos y con el parámetro p hacemos que imprima el resultado. Este comando es útil cuando sabemos que el contenido que estamos buscando está en un rango de líneas.
Si queremos mostrar el rango de líneas de la 2795 a la 2800 del fichero poblacion.csv
sed -n 2795,2800p poblacion.csv
3.- COMANDOS ENCADENADOS
Hasta ahora hemos visto distintos comandos que se ejecutan de manera independiente con funcionalidades únicas, pero seguro que nos sería de interés poder hacer una operación y sobre el resultado hacer otra operación distinta, luego otra… hasta tener el resultado que deseamos.
Esto es posible mediante el uso de pipes, o tuberías, y se representa con una línea vertical |. El funcionamiento consiste en que un comando va escribiendo su resultado mientras que otro va leyendo lo que se está escribiendo, de esta manera el comando que está leyendo de un pipe puede estar escribiendo en otro y así sucesivamente.
Para entender cómo se utiliza vamos a ver algunos ejemplos en los que en lugar de utilizar un único comando, lo hacemos con varios encadenados.
Aunque el comando find nos permite realizar muchas operaciones, si la sintaxis se nos hace espesa, podemos utilizar varios comandos pasando la salida de uno como entrada para otro. Por ejemplo, para filtrar resultados devueltos por find podemos utilizar el comando grep (pasando el parámetro -F para indicarle que es un literal y no una expresión regular)
find . -type f -name '*.log.*' es equivalente a find . -type f | grep -F '.log.' Ambas ejecuciones devolverán los mismos resultados. En el segundo caso lo que estamos haciendo es listar todos los ficheros (find . -type f ) y, sobre esta lista de ficheros, mostrar únicamente los que en su nombre contienen .log. (grep -F '.log.')
find . -type f -name '*.log.*' -exec rm {} \; es equivalente a find . -type f | grep -F '.log.' | xargs rm. En este caso hacemos uso de xargs, este comando hace que se le pasen los valores filtrados por grep como parámetros de entrada al comando rm. Si no utilizáramos xargs, el comando rm nos devolvería un error porque se le está llamando sin parámetros

Para hacer una búsqueda dentro de un fichero lo podemos hacer con el comando grep. Por ejemplo, para buscar ficheros que contengan la palabra test y además la palabra log en su nombre. Y sobre esos ficheros, queremos buscar las líneas que contengan la cadena ERROR
find . -type f | grep 'test' | grep log | xargs grep ERROR
NOTA: En el ejemplo anterior se ha utilizado varias veces el comando grep. Las dos primeras está filtrando ficheros cuyo nombre coincidan con un patrón, el último, lo está haciendo con el contenido del fichero, es decir, está buscando dentro del fichero. La diferencia se que antes se le está poniendo xargs.
4.- REDIRECCIONES
Todos los comandos que hemos visto, por defecto, nos muestran los resultados y los errores por pantalla; si los resultados son pocos, lo mismo nos sirve verlos así, pero si el número de resultados es amplio lo que realmente nos interesaría es guardarlos en un fichero. Esto lo podemos hacer de una manera muy fácil, con una redirección de la salida estándar. Para ello únicamente tenemos que poner > al final de los comandos que vamos a ejecutar e indicar el la ruta y nombre del fichero donde queremos que nos guarde dichos resultados.
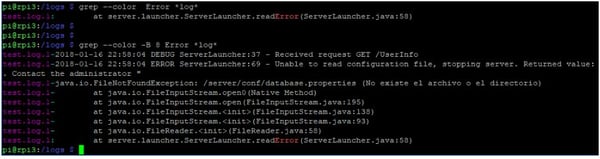
grep -i error *log > /tmp/salida_errores.log
Esto nos dejará en el fichero /tmp/salida_errores.log el resultado de ejecutar grep -i error *log
5.- CONCLUSIONES
Con estos simples ejemplos hemos podido ver que con una simple línea podemos hacer búsquedas de archivos considerablemente detalladas. Además, hemos aprendido cómo encadenar comandos para pasar las salidas de unos a otros. Si comparamos el tiempo que lleva hacer alguna de estas acciones con comandos linux frente a otras opciones, como por ejemplo copiarlos a nuestro local para hacerlo con herramientas alojadas en nuestros ordenadores, veremos que gana por goleada el hacerlo directamente en el servidor con comandos.
Además, estamos utilizando programas que se crearon hace más de 40 años para las máquinas que había entonces, con la diferencia que ahora lo ejecutamos en máquinas con una potencia de cálculo increíblemente mayor, y es que en pocos sitios vamos a poder ver optimizaciones y gestión de recursos tan buenas como las que tienen los comandos de linux. Compáralo con la ejecución de programas actuales ¿cuánto tarda en ejecutarse tu programa para ver logs? ¿cuánta memoria consume?
En cualquier caso, creo que para muchas acciones no es que con esto tengamos una opción, si no que debería ser la única. Si tienes en tu servidor un fichero de logs de 8GB, dudo que nadie se plantee el copiarlo a su ordenador para luego abrirlo con el notepad. Definitivamente deberías analizarlo directamente en el servidor y, posteriormente, deberías ver por qué tienes un fichero de tan elevado tamaño y no partido en más pequeños, pero eso ya sería otro problema.
De la misma manera que con SQL te puedes ver limitado a la hora de hacer determinadas operaciones y pasar a PL/SQL, si continúas explorando el mundo de los comandos linux llegará un momento en el que se pueden quedar “cortos”. En ese momento es cuando pasamos al mundo del shell scripting, teniendo scripts que ejecutan estos comandos y permiten añadir toda la lógica que podamos necesitar. Y si necesitamos tratar los ficheros, podrás empezar a utilizar awk (1977) que es un lenguaje de programación diseñado únicamente para tratar datos que tengamos en texto, así que mal no lo tiene que hacer.
Simplemente hemos visto algo de búsqueda en ficheros, pero puede ser el punto de entrada para un sinfín de opciones, como monitorización de sistemas, CPU, memoria, consumo de ancho de banda, utilización de puertos…Hay una frase que me gusta mucho decir: “la consola, nunca miente”. Si ves algo por consola y en otra herramienta ves algo distinto, siempre apostaría por la consola.
Espero haber dado una ligera idea de las grandes cosas que hay detrás de esa pantalla negra, de sus bondades y de sus limitaciones, pero por lo menos de su existencia.