

![]()
Muchas veces nos hemos visto en la tesitura de tener que volver a una versión anterior del código que subimos en la última implantación, deshacer los cambios incluidos en alguna rama de desarrollo o comenzar nuevos evolutivos, manteniendo la estabilidad de lo que ya tenemos en producción.Dentro del mundo de desarrollo de aplicaciones, tenemos varias herramientas que permiten realizar estas acciones: herramientas basadas en control de versión del software.
A grandes rasgos, existen dos modelos de trabajo en los que nos podemos basar:
-
Modelo cliente-servidor: existe un repositorio central al cual se accede mediante un cliente en cada una de las máquinas de los desarrolladores (CVS o SCV).
-
Modelo distribuido: cada desarrollador trabaja directamente con un repositorio local y, posteriormente, los cambios se comparten entre repositorios (GIT).
En la actualidad, aparte de por todos los beneficios que ello conlleva y, sobre todo, por la agilidad que aporta en la manera de trabajar en nuestro día a día; la tendencia es mirar hacia un modelo distribuido donde resalta con fuerza el nombre de GIT.
¿Qué es GIT?
GIT es un software de control de versiones diseñado por Linus Torvalds, creado pensando en la eficiencia y la confiabilidad del mantenimiento de versiones de aplicaciones cuando éstas tienen un gran número de archivos de código fuente. Su propósito es mantener un registro de los cambios realizados sobre los ficheros del repositorio y coordinar el trabajo que varias personas realizan sobre archivos compartidos.
El diseño de Git está basado en BitKeeper y en Monotone y, al principio, se pensó como un motor de bajo nivel sobre el cual otros pudieran escribir la interfaz de usuario (frontend) como Cogito o StGIT:
- BitKeeper: sistema de control de versiones distribuido para el código fuente de los programas producidos a partir de BitMover Inc.
- Monotone: registra revisiones de ficheros, agrupa conjuntos de revisiones ('changesets') y mantiene el histórico tras cambios de nombre. Cada participante mantiene su propio almacén de revisiones históricas en una base de datos SQLite local.
Sin embargo, Git se ha convertido desde entonces en un sistema de control de versiones con funcionalidad plena 1, hasta tal punto de que proyectos de gran relevancia, como es el grupo de programación del núcleo de Linux, ya lo usan.
Gestión de ficheros en GIT
La principal diferencia entre Git y cualquier otro SCV es la manera en la que modela sus datos. Conceptualmente, la mayoría de los demás sistemas almacenan la información como una lista de cambios en los archivos, a lo largo del tiempo.
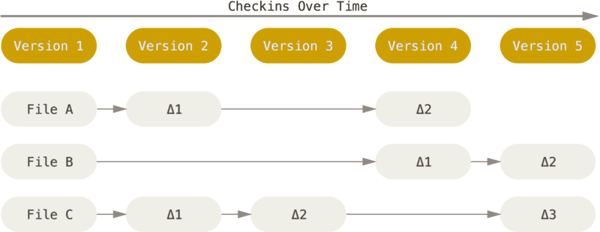
Mientras que Git modela sus datos como un conjunto de instantáneas de un minisistema de archivos, es decir, hace una foto del aspecto del proyecto en un momento determinado. Para no perder eficiencia, si un archivo no se modifica no se almacena de nuevo, solo se enlaza al archivo anterior que ya tiene almacenado.
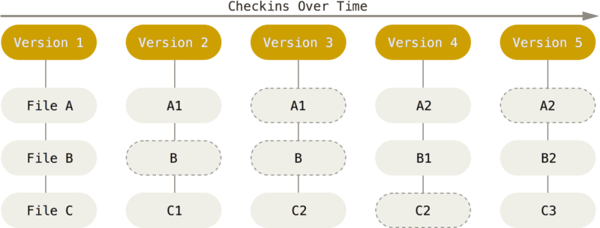
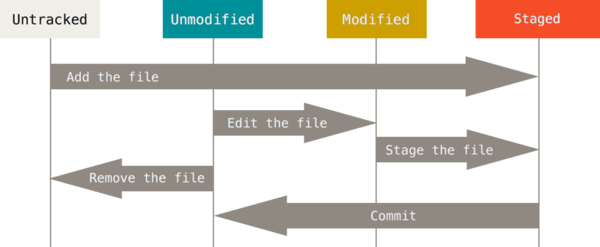
Para gestionar los cambios en el repositorio, Git trabaja con dos tipos de ficheros:
-
Untracked: ficheros sin seguimiento, es decir, ficheros que no existían en la última instantánea realizada y por tanto son nuevos.
-
Tracked: ficheros en seguimiento y, por tanto, ya existentes en la última instantánea realizada. Dentro de este grupo, podemos encontrar los siguientes estados:
-
Unmodified: fichero sin cambios.
-
Modified: fichero con modificaciones realizadas.
-
Staged: fichero preparado para ser volcado en el repositorio.
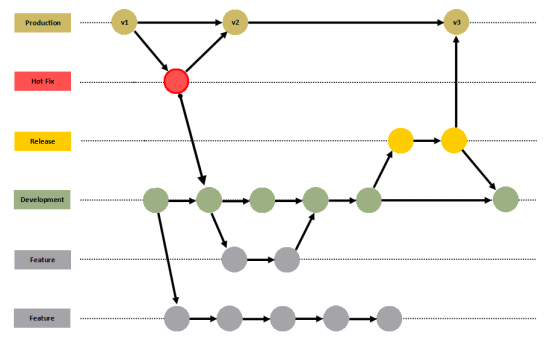
Branching en GIT
Otro de los aspectos que hace de Git una herramienta idónea para el control de versiones es su sistema de ramificaciones, tanto por el número distinto de tipos de ramas como por la rapidez en su manejo para avanzar o retroceder.
Aunque cada desarrollador o equipo de desarrollo puede hacer uso de Git de la forma que le parezca más conveniente, una buena práctica para comenzar en este mundo es la expuesta por Vincent Driessen en su publicación “A successful Git branching model” de enero 2010 2.
En su artículo compartía, por primera vez con la comunidad, este modelo de ramas. Vincent reconocía 5 tipos diferentes sobre las que trabajar según el tipo de desarrollo a realizar: Master, Development, Feature, Release y Hotfix.
- Master
Es la rama principal y contiene el repositorio que se encuentra publicado en producción, por lo que debe estar siempre estable.
- Development
Es una rama sacada de master y se conoce como la rama de integración, por lo que todas las nuevas funcionalidades se deben integrar en esta rama. Una vez integrado el código y corregido los errores, en caso de que los hubiera, si la rama está estable, se puede hacer un merge sobre la rama master.
-
Feature
Cada nueva funcionalidad se debe realizar en una rama nueva y específica para esa funcionalidad. Éstas se deben sacar de development y una vez que la funcionalidad esté desarrollada, se hace un merge de la rama sobre development, donde se integrará con las demás funcionalidades.
-
Release
Ramas creadas desde la rama develop y se utilizan para preparar el código antes de integrar en master para tener una versión lista para desplegar en producción. En esta rama no se deben realizar grandes cambios, tan solo fallos menores o modificación de número de versiones. Los cambios realizados es esta rama, además de integrarse con la rama de producción, se deben volcar también a la de desarrollo.
-
Hotfix
Son bugs que surgen en producción, por lo que se deben arreglar y publicar de forma urgente. Es por ello que son ramas sacadas de master y una vez corregido el error, se deben volcar dichos cambios sobre la rama de producción. Una vez hecho esto, para mantener alineadas las ramas de producción y de desarrollo, es necesario actualizar esta última con los cambios incluidos en la primera.
Comunicación en GIT
Para la transferencia de datos, Git puede hacer uso de cuatro protocolos distintos, los cuales deberemos utilizar según las circunstancias en las que nos encontremos:
-
Protocolo local
Es el más básico de todos, ya que el repositorio remoto está en otro directorio del mismo disco. Útil cuando todos los componentes del equipo tienen acceso a un mismo sistema de archivos, o en el caso en el que todos se conecten al mismo ordenador, aunque ésto no es muy recomendable desde el punto de vista de rendimiento.
-
Protocolo SSH
Es el más habitual de todos, ya que es un protocolo que permite fácilmente leer y escribir; aparte de proporcionar mecanismos de autenticación sencillos de usar y habilitar, ya que los demonios de red SSH son de uso común. Por el contrario, no se aconseja utilizar en proyectos abiertos, ya que no permite acceso de forma anónima.
- Protocolo Git:
Es un demonio incorporado en el framework que escucha por el puerto dedicado 9418 y proporciona un servicio similar a SSH pero sin autentificación ni encriptación, por lo que es útil para proyectos abiertos con mucho tráfico.
- Protocolo HTTP/S:
Su potencia radica en la facilidad para habilitarlo y en la cantidad mínima de recursos que necesita. Si queremos las transferencias encriptadas podemos aplicar HTTPS, pudiéndose incluir certificado SSL para cada usuario.
Conclusión
Una vez que hemos abierto la puerta al mundo GIT y hemos conseguido sentar unos buenos cimientos para entender cómo funciona este método de control de versiones, llega el momento de poner estos conocimientos básicos en práctica.
Para ello, en posteriores publicaciones hablaremos de Gitflow, algo que está muy de moda en el mundo Git, y que muchos de nosotros habremos utilizado alguna vez sin saber que lo estábamos haciendo.
A modo de introducción, Gitflow es un conjunto de extensiones para Git que proporciona acciones de alto nivel para trabajar con el modelo de ramificaciones propuesto por Vincent Driessen.
El resultado final es disponer de un catálogo de comandos para automatizar diferentes tareas que se realizan a la hora de crear ramas, publicar cambios, controlar las releases y puestas en producción, así como la resolución de bugs.
Como podemos ver, cada paso que damos hacia adelante es para mejorar el presente. ¡Suscríbete a nuestro blog y no te lo pierdas!


.png?width=352&name=Copilot%20-%20Evento%20%20(4).png)