


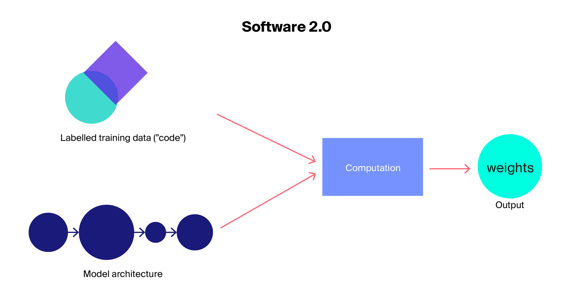
The term Software 2.0 was coined by Andrej Karpathy, a computer scientist and former senior director of AI at Tesla, to describe machine learning (ML) models that assist in solving a variety of classification and recognition problems without the traditional human input of writing a single line of code. It's a new kind of software that "is written in much more abstract, human unfriendly language, such as the weights of a neural network."
Software 2.0 is based on deep learning, where the developer will merely gather data to feed ML systems. The concept of interpretability does not matter for most domains (apart from some safety-sensitive ones) and the concept also seems to be more research-oriented in terms of R&D.
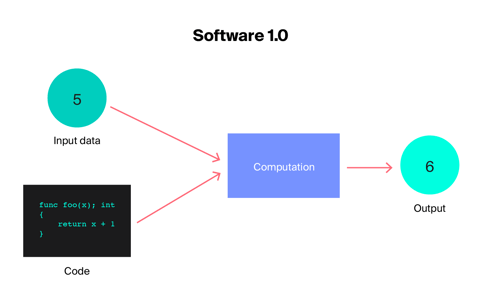
Software 1.0 vs. Software 2.0: Resources writing the code to dictate software behavior vs. the code being discovered by calculations.
Advantages of Software 2.0
This shift from traditional programming to connectionist ML makes software development a lot easier day to day. Some of the factors driving Software 2.0 are:
- Computationally alike: A neural network combines the two processes of matrix multiplication and thresholding at zero (ReLU) and is far more complicated and diverse than the instruction set of traditional software. It’s very possible to create a variety of performance guarantees, as you only need to provide Software 1.0 implementation for a handful of the fundamental processing primitives (like matrix multiply).
- Embedding in chips: Since a neural network's set of instructions is relatively short, it is easy to construct these networks on hardware that is closer to silicon, such as neuromorphic chips, customized ASICs, etc.
- Constant run time: A traditional neural network forward pass requires the same number of floating-point operations (FLOPS) for each and every iteration. No variation is feasible based on the various execution routes which codes might choose through a sizable C++ code base. Dynamic compute graphs are possible, although the execution flow is typically restricted. This almost guarantees that users will never get caught in an unforeseen infinite loop.
- Modules can patch into an optimized whole: Software is typically broken up into various modules that connect via open APIs, endpoints, or public functions. However, users can quickly backpropagate through the entire system if there are two distinct Software 2.0 modules that were trained to interact separately. This is a default behavior with Software 2.0.
- Process agility: It is quite difficult to adapt a system to meet new requirements if it has a C++ language code and needs to work two times faster (even at the expense of performance). With Software 2.0, users can choose the network, remove half of the channels, retrain, and the result will work exactly twice as fast.
Challenges of Software 2.0
- Teams with varied skills: Strong cross-functional teams that can handle the dangers of AI and ML will be necessary. The teams must bring a wide range of expertise, starting with domain knowledge, design, privacy, ethics, and compliance. Organizations must also take into account the various social and cultural backgrounds of the group and how that may impact buy-in or rejection of Software 2.0 concepts.
- Explainability of ML model: Sometimes it is difficult to explain why the software behaves in a particular way. Explainability is crucial in many fields, such as medicine and law, where at times the application of Software 2.0 becomes a challenge.
From the perspective of many programmers, Software 2.0 inherits additional challenges from ML libraries:
- Dependence on data: As a result of learning rules from training data, ML algorithms create ML models that contain the learned rules. The training data determines how accurate ML models' judgments will be.
- Dependence on pre-trained model: Software 2.0 uses trained ML models in production environments to make choices (e.g., identify an email as spam or not spam).
- Evolving rapidly: Both new and improved ML algorithms are being developed by researchers. As a result, ML libraries that use these techniques undergo fast modification and routinely release new versions.
- Requirement for optimized hardware: To effectively train ML models, ML libraries typically need hardware that has been optimized, such as GPU and TPU. Due to these distinctive characteristics, the use of ML libraries requires special consideration from researchers.
Use cases and examples
- Moderating content: Every day, sensitive image, video, text, and audio content is removed from user-generated content streams using AI models. Advertisers can identify content that is off-brand or of low quality, as well as detect and regulate inappropriate language and profanity in text posts and unsuitable text in photos.
- Facial and speech recognition: Face comparison, face matching, face searching, and face-based identity verification are all common use cases, providing secure entry to workplaces, schools, airports, and devices. Additionally, neural networks can be used for speech recognition.
- Predictive maintenance: Computer vision technology is being used by manufacturers, airlines, and agricultural companies to save maintenance and inspection expenses and lengthen the lifespan of capital assets. Software 2.0 has the potential to significantly improve asset efficiency, asset planning, asset monitoring, and maintenance planning.
|
Prisma Labs |
Prisma Labs, a Singapore-based photo-editing mobile application, uses neural networks and AI to apply artistic effects to transform images. It utilizes the recent neural style transfer technology to redraw an image using another image style. |
| Rosebud AI |
Rosebud is a US-based company offering a variety of Software 2.0 solutions under the heading of AI-generated media, using Deepfake AI and the latest in Generative Adversarial Networks (GANs). Its goal is to “enable game [video] game creation at the speed of thought.” |
| Otter.ai |
Otter is a US-based AI transcribing solution that is compatible with common video conferencing programs. |
| Grammarly |
Grammarly is a US-based company for digital writing assistance powered by AI. |
Future of Software 2.0 and its impact on workforce
Emerging ML technology addresses many of the challenges and complexities that hold up or delay the creation and use of AI models and are predicted to expedite the development of Software 2.0. Software 2.0 will become increasingly crucial in any field where repeated evaluation is practical, affordable, and difficult to explicitly design.
- According to an MIT/BCG study, 84% of respondents believe AI is essential to gaining or maintaining a competitive advantage, and 3 out of 4 respondents think ML offers a chance to start new enterprises and that AI will be the foundation for new entrants into their sector.
- As per a report by Fortune Business Insights, the global software-as-a-service (SaaS) market stood at USD 113.82 billion in 2020. The market is expected to grow from USD 130.69 billion in 2021 to USD 716.52 billion in 2028 at a CAGR of 27.5% during the period. This increased demand for the SaaS market will also act as a driver for Software 2.0.
The emergence of Software 2.0 will alter not only how software is built but also who works on it. Software 2.0 will require collaboration between domain experts and data scientists. This means additional skills at the hands of developers. In fact, according to a survey by Evans Data Corp (a US-based market research firm), nearly 30% of software developers believe that their development efforts will be replaced by AI in the foreseeable future.
This is expected to give rise to the 2.0 programmers who will have proficiency in AI projects including math, algebra, calculus, statistics, big data, data mining, data science, ML, cognitive computing, text analytics, natural language processing, R, Hadoop, Spark, and many others.
According to Andrej Karpathy, Software 2.0 is changing the programming paradigm by splitting teams into two. Karpathy sees a future where 2.0 programmers will manually curate, maintain, massage, clean, and label datasets, while 1.0 programmers will maintain the surrounding tools, analytics, visualizations, labeling interfaces, infrastructure, and training code.


