


Os algoritmos de aprendizagem de máquinas são tipicamente capazes de extrair informações importantes de conjuntos de dados ricos em características, quer sejam tabelas com muitas colunas e filas ou imagens com milhões de pixels. Junte isto a avanços na computação em nuvem, e o resultado é que modelos de aprendizagem de máquinas cada vez maiores podem ser executados com grande potência.
Contudo, cada característica que é adicionada aumenta a complexidade do executável, o que torna a localização da informação utilizando estes algoritmos poderosos também complicada. A solução é a redução da dimensionalidade, que consiste em empregar um conjunto de técnicas para remover características excessivas e desnecessárias dos modelos de aprendizagem mecânica.
A redução da dimensionalidade também reduz drasticamente o custo da aprendizagem da máquina e permite resolver problemas complexos com modelos simples.
Esta técnica é especialmente útil em modelos preditivos, pois são conjuntos de dados que contêm um grande número de características de entrada, e torna a sua função mais complicada.
Portanto, a técnica de redução da dimensão é definida como uma forma de converter um conjunto de dados de alta dimensão num conjunto de dados de dimensão inferior, assegurando que a informação que fornece é semelhante em ambos os casos. Como mencionado, esta técnica é frequentemente utilizada na aprendizagem de máquinas para obter um modelo de previsão mais apertado, resolvendo ao mesmo tempo os problemas de regressão e classificação apresentados pelos algoritmos.
Dados de alta dimensão, reconhecimento de voz, visualização de dados, redução de ruído ou processamento de sinais, entre outros, são os principais campos de aplicação da redução da dimensionalidade.
Problemas de dimensionalidade
Entrando em detalhes sobre os problemas de dimensionalidade que aparecem nos modelos de Aprendizagem Automática, temos primeiro de saber que estes modelos são responsáveis pela atribuição de características aos resultados. Por exemplo, um modelo meteorológico preditivo tem um conjunto de dados de informações recolhidas de diferentes fontes. Estas fontes incluem dados sobre temperatura, humidade, velocidade do vento. Bilhetes de autocarro comprados, tráfego e quantidade de chuva de diferentes alturas no mesmo local. Como se pode ver, nem todos os dados são relevantes para a previsão do tempo.
Por vezes, algumas características não estão relacionadas com a variável alvo. Outras características podem estar correlacionadas com a variável alvo, mas não têm qualquer relação específica com ela. Também pode haver ligações entre a característica e a variável alvo, mas o efeito é insignificante. No exemplo acima, é claro quais são as características úteis e quais não são, mas noutros problemas a diferença pode não ser óbvia e pode exigir mais análise de dados.
A redução da dimensão pode não parecer fazer sentido, porque quando existem demasiadas características, será também necessário um modelo mais complexo com mais dados de formação e mais poder computacional para treinar adequadamente o modelo. Contudo, os modelos não compreendem o acaso e tentam atribuir qualquer característica incluída no seu conjunto de dados à variável alvo, mesmo que não exista uma relação de acaso, gerando modelos errados. Ao reduzir o número de características, é possível obter um modelo mais simples e mais eficiente.
A redução da dimensionalidade é responsável pela identificação e remoção de características que diminuem o desempenho do modelo de aprendizagem da máquina. Além disso, há várias técnicas de dimensionalidade que serão discutidas abaixo, cada uma das quais é útil para certas situações.
Como reduzir a dimensionalidade?
Entre os métodos mais básicos de redução da dimensão, o mais eficiente é identificar e seleccionar um subconjunto de características que sejam altamente relevantes para a variável alvo. Esta técnica é conhecida como selecção de características, e é particularmente eficaz quando se trata de dados tabulares em que cada coluna representa um tipo específico de informação.
A selecção das características faz principalmente duas coisas: mantém características altamente relacionadas com a variável alvo e contribui mais para a variação do conjunto de dados. Por exemplo, Python tem uma biblioteca, conhecida como Scikit-learn, que tem funções para analisar e seleccionar características adequadas para modelos de Aprendizagem Automática.
Um aspecto comum é utilizar gráficos de dispersão e mapas de calor para visualizar a covariância de diferentes características, ou seja, estas ferramentas são utilizadas para descobrir se duas características estão altamente relacionadas entre si e se terão um efeito semelhante na variável alvo, para determinar que não é necessário incluir ambas no modelo, eliminando uma delas sem afectar negativamente o desempenho. Da mesma forma, as variáveis que não contribuem com informação para a variável alvo são removidas.
Um exemplo pode ser um conjunto de dados de 25 colunas que pode ser representado por apenas 7 delas, capazes de representar 95% do efeito sobre a variável alvo. Assim, podem ser eliminadas até 18 funções, simplificando o modelo de aprendizagem da máquina sem perder eficiência.
Geralmente, quando ocorre a redução da dimensionalidade, perde-se até 15% da variabilidade dos dados originais, mas traz consigo vantagens tais como menor tempo de treino, requer menos recursos computacionais e aumenta o desempenho global dos algoritmos. Além disso, a redução da dimensionalidade resolve o problema do sobreajustamento. Quando há muitas características, os modelos tornam-se mais complexos e tendem a sobreajustar-se; graças à redução, este problema desaparece. Por sua vez, a redução cuida da multicolinearidade, que ocorre quando uma variável independente está altamente correlacionada com uma ou mais variáveis independentes, pelo que a redução combina estas variáveis num único conjunto.
Por outro lado, esta técnica é também muito útil para a análise de factores, uma abordagem que trata da localização de variáveis latentes que não são medidas directamente numa única variável, mas inferidas a partir de outras variáveis do conjunto de dados, onde as variáveis latentes são conhecidas como factores. Também elimina o ruído nos dados, mantendo apenas as características mais importantes e removendo as redundantes, melhorando assim a precisão do modelo.
No campo das imagens, é muito útil para a compressão de imagens, permitindo que o tamanho em bytes seja minimizado mantendo ao mesmo tempo grande parte da qualidade da imagem. Basicamente, os pixels que compõem uma imagem são considerados como variáveis dos dados da imagem. Utilizando a análise de componentes principais (PCA), é mantido um número óptimo de componentes para equilibrar a variabilidade e a qualidade da imagem.
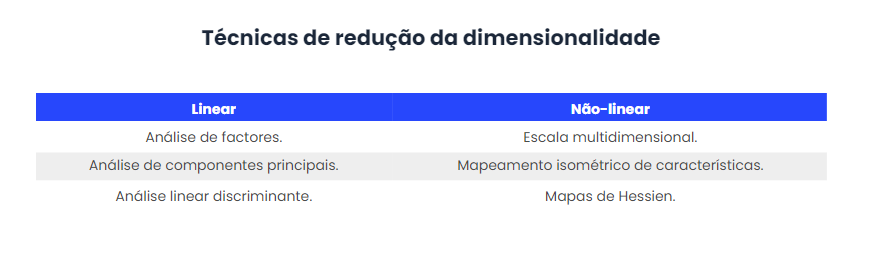
Finalmente, estas técnicas são diferenciadas entre lineares e não lineares, sendo algumas das mais proeminentes:
Vantagens e desvantagens das técnicas de redução da dimensionalidade
Algumas das principais vantagens da aplicação da técnica de redução da dimensionalidade são as seguintes:
- A redução das dimensões das características implica uma redução do espaço necessário para armazenar o conjunto de dados, porque o conjunto de dados também é reduzido.
- O tempo de formação do modelo é mais curto para dimensões reduzidas.
- A visualização mais rápida dos dados é facilitada pela redução do número de características no conjunto de dados.
- As características redundantes no domínio da multicolinearidade desaparecem.
A redução da dimensão também tem algumas desvantagens que são mencionadas abaixo, embora as vantagens sejam maiores:
- Alguns dados podem perder-se devido à redução da dimensionalidade.
- Na técnica de redução da dimensionalidade da APC, os principais componentes a considerar por vezes não são conhecidos.
Conclusões
Em suma, ter demasiadas características resultará num modelo de aprendizagem mecânica ineficiente. Contudo, a capacidade de reduzir características através da redução da dimensionalidade é uma ferramenta que pode ser utilizada para criar modelos mais optimizados e eficientes.
A redução da dimensão pode ser aplicada a diferentes campos, tais como dados de alta dimensão, reconhecimento da fala, visualização de dados, redução de ruído ou processamento de sinais, entre outros. Também pode ser utilizado para transformar dados não lineares numa forma linearmente separável.
A utilização desta técnica traz benefícios significativos que vão desde a redução do espaço de armazenamento do conjunto de dados até à eliminação de características redundantes, optimizando o tempo de formação do modelo e facilitando a visualização dos dados. No entanto, é uma técnica que requer conhecimento e equipamento apropriado para ser executada, uma vez que podem ser retirados mais dados do que o necessário e gerado um modelo errado.


